Overview
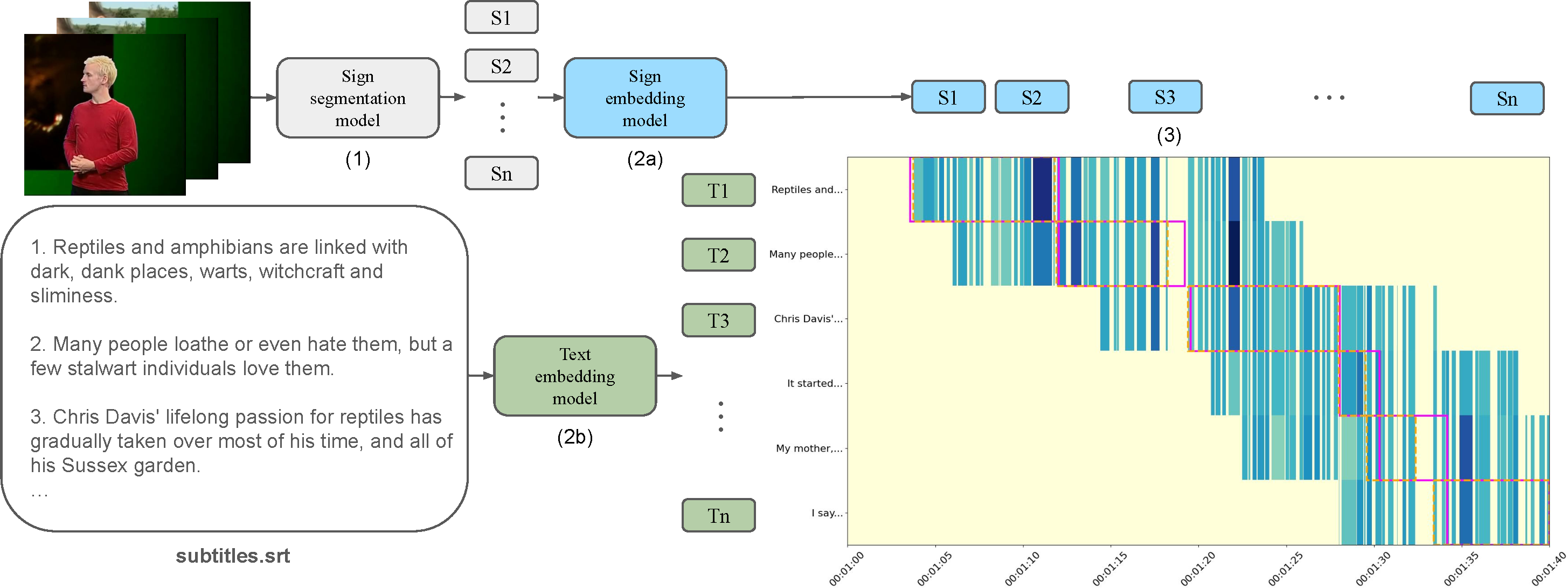
The goal of this work is to develop a universal approach for aligning subtitles (i.e., spoken language text with corresponding timestamps) to continuous sign language videos. Prior approaches typically rely on end-to-end training tied to a specific language or dataset, which limits their generality. In contrast, our method Segment, Embed, and Align (SEA) provides a single framework that works across multiple languages and domains. SEA leverages two pretrained models: the first to segment a video frame sequence into individual signs and the second to embed the video clip of each sign into a shared latent space with text. Alignment is subsequently performed with a lightweight dynamic programming procedure that runs efficiently on CPUs within a minute, even for hour-long episodes. SEA is flexible and can adapt to a wide range of scenarios, utilizing resources from small lexicons to large continuous corpora. Experiments on four sign language datasets demonstrate state-of-the-art alignment performance, highlighting the potential of SEA to generate high-quality parallel data for advancing sign language processing. SEA's code and models are openly available.
Talk at BMVA
Datasets
Episode-level train/val/test splits used in this work are available at github.com/J22Melody/SEA/data.
Qualitative Results

5224144816887051284)
ETOZLBScxWY-3-rgb_front)
srf.2020-03-13)
2023-02-16_ein_hund_fürs)Qualitative Results: for each dataset, we sample a 30-second validation clip and show keyframes every 2 seconds. Rows: predicted signs from the segmentation model (yellow), original subtitles (green), SEA-aligned subtitles (blue), and expert-aligned ground truth (purple). In general, segmentation identifies the signing frames of interest; SEA then shifts subtitles toward higher text–sign similarity—for example, in BSL the first subtitle begins at the fingerspelling AMPNIBIS (“amphibians”) and ends at the sign for “sliminess”.
Acknowledgements
The BOBSL images in this paper are used with the kind permission of the BBC.
ZJ is funded by the Swiss Innovation Agency (Innosuisse) flagship IICT (PFFS-21-47). This work was supported by the ANR project CorVis ANR-21-CE23-0003-01, the UKRI EPSRC Programme Grant SignGPT EP/Z535370/1, and a Royal Society Research Professorship RSRP\R\241003, the Institute of Information & Communications Technology Planning & Evaluation (IITP) grant funded by the Korean government (MSIT, RS-2025-02263977, Development of Communication Platform supporting User Anonymization and Finger Spelling-Based Input Interface for Protecting the Privacy of Deaf Individuals).